2 基于FPGA的ANN实现方法
经典实现方法有:
(1)可重构的RNN结构(Reconfigurable NeuraINetwork)
可重构计算是一种增加处理密度(每单元硅片面积的性能)的有效方法,且处理密度远大于用于通用计算方法,FPGA作为可重构计算的平台,可以提供如同软件一样的设计灵活性。该方法基于可扩展的脉动阵列结构、可重用的IP(Intellectual Properties)核及FPGA器件,即将要实现的神经网络算法分为几种基本运算,这些基本运算由可重构单元(Reconfigurable Cell,RC)完成,RC间以规则的方式相互连接,当神经网络变化时,只要增减Rc的数量或替换不同功能的RC就可重构成新的神经网络硬件;文献[8]中同时指出,考虑到硬件实现要以最少的硬件资源满足特定应用的性能需求,一般用神经元并行作为可重构部件的基本模式,即神经网络的各层计算可复用相同的阵列结构。
(2)RENCO结构
可重构网络计算机(Reconfigurable Network Computer,RENCO)是一种用于逻辑设计原型或可重构系统的平台,所设计的可重构系统对于工作在比特级的算法实现特别有效,比如模式匹配。RENCO的基本架构包括处理器、可重构部分(多为FPGA)以及存储器和总线部分,Altera公司提供的最新的RENCO在可重构部分包括近100万逻辑门,足够实现高复杂度的处理器。具体参见文献[9]。尽管如此,得到的可重构系统并非对所有的硬件实现都是优化的方法,比如不适合于浮点运算。
(3)随机比特流方法
随机比特流(Stochastic Bit Strearns)的方法是使用串行随机的方法实现一些运算操作,目的是为了节约资源和充分利用神经网络的实时性。随机算法的提出源于它的简易性,基本原理即首先将所有的输入转换成二进制随机比特流,就是任意化;然后,由数字电路组成的随机算法实现取代正常的算法;最后,随机比特流转回到正常的数值(文献[10]中有详细总结)。随机算法提供一种方法,用简单的硬件实现复杂的计算,同时又不失灵活性,而且随机实现又与现代VLSI设计和生产技术兼容。
FPNA实现方法:
凭借着简化的拓扑结构和独特的数据交换流图,FPNA(Field Programmable Neural Arrays)成功地解决了以简单的硬件拓扑结构有效地实现复杂的神经架构问题,是一种特别适合FPGA直接实现的神经计算范例。FPNA基于一种类似FPGA的结构:它包含一系列可以自由配置的资源,这些神经资源被定义用来实现标准神经元的计算功能,但是它们是一种自主的方式,这样通过有限的连接可以创造出许多虚拟的连线。利用这种新的神经计算理念,一个标准的但结构复杂的神经网络可以由一个简化的神经网络替代(文献[11]给出了详细的数学表示和说明)。
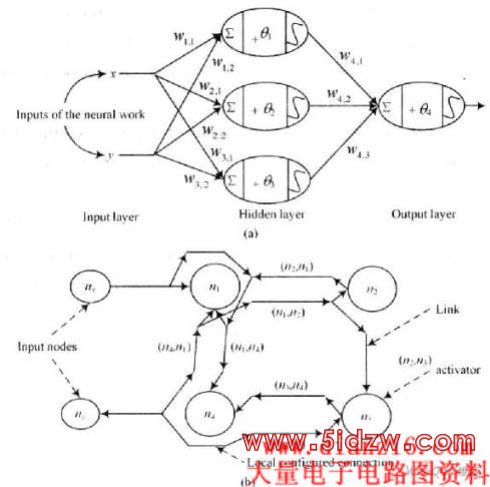
为了有个直观的理解,图3(a)表示一个简单的MLP结构;图3(b)说明通过节点间的直接连接建立虚拟连接。
文献[11]中的例证表明FPNA计算范例确实允许一系列给定的神经资源代替具有不同架构的标准神经网络。然而,从图4中可能并非如此,MLP架构并没有得到简化,原因在于如此简单的MLP完全没有必要,也不可能再简化。文献[12]描述了大型神经网络得到明显简化的实例。需要注意的是,FPNA是一个适应神经计算的硬件框架,而不是一种处理简化神经计算的实现方法(Field Programmable Neural Network,FPNN)。要设计一个FPNA,首先要选择一个针对应用的合适的标准神经架构,然后决定一个既适合于实现又在功能上等价于所选择神经网络的可配置FPNA,FPNA独特的计算方案在于在复杂神经网络和可用的硬件资源之间创造了一座桥梁,它适用于许多实现选择;最后,得到的FP-NA直接映射到硬件设备上,这将得益于完整的模块式实现,即对于每个神经资源,预先给定可配置模块,然后依照。FPNA硬件友好的架构进行组合。
3 基于FPGA的神经网络的性能*估及局限性
对于FPGA实现的ANN,最普遍的性能*估方法是每秒神经元乘累加的次数(Connections-Per-Sec-ond,CPS)和即每秒权值更新的次数(Connections-Updates-Per-Second,CPUS)。但是CPS和CPUS并不是适于所有的网络,如RBF径向基网络,另外,更大的CPS和CPUS值并不一定意味着更好的性能。因此,最好的性能测量方法是实际执行时间,但是仍有些问题要讨论。FPGA实现神经网络存在的一些缺点(相对于计算机软件而言):
(1)FPGA上实现的神经网络大多数是计算结构,而不是认知结构(虽然现在有些人试图在FPGA上实现BP算法。但是整个的结构和时序控制变得很复杂,并且无法达到计算机软件那样的计算精度);
(2)在FPGA上实现的神经网络通用性差。目前FPGA的使用者大多数都是在RTL级(寄存器传输级)编写VHDL/Verilog HDL实现数字系统,而正在兴起的Handel-C&SystemC,可以使硬件编程者站在算法级角度,可能对以后的基于FPGA的神经网络的性能有所改善。
4 基于FPGA实现神经网络的发展方向
(1)一种基于REMAP-β实现神经网络汁算机的方法。REMAP-β可重构架构基于FPGA技术,RE-MAP-β并行计算机应用在嵌入式实时系统中,以有效提高ANN算法实现的效率,目前它的进一步发展RE-MAP-r正在探讨中。
(2)另一种基于FPGA实现神经网络的发展方向――系统C语言,直接在可编程硬件平台支持C/C++,使得编程更加容易。但是这个转换并不容易,因为:FPGA不是程序,而是电路。
5 结 语
详细总结了FPGA实现神经网络的方法及相关问题,这里要注意,基于FPGA实现神经网络,并不是要与基于计算机软件实现一比高低,相反,在很多情况下,采用计算机软件测试神经网络的收敛情况,计算出收敛时的权值,然后通过数据口线与FPGA模块通信,把权值交给FPGA中的神经网络,使用FPGA完成现实的工作。直到现在,软件方法仍然是实现神经网络的首选。另外,对于硬件设计者(指利用FPGA或者全定制、半定制ASIC实现设计)而言,mask ASICs提供首选的方法以得到大规模、快速和完全的神经网络。现在它已经开发出了所有的新型可编程器件的嵌入式资源,以得到可以实时训练的更有用的神经网络。
,基于FPGA的人工神经网络实现方法的研究